Deployment¶
In this series we’ve been exploring a structured controller development workflow.
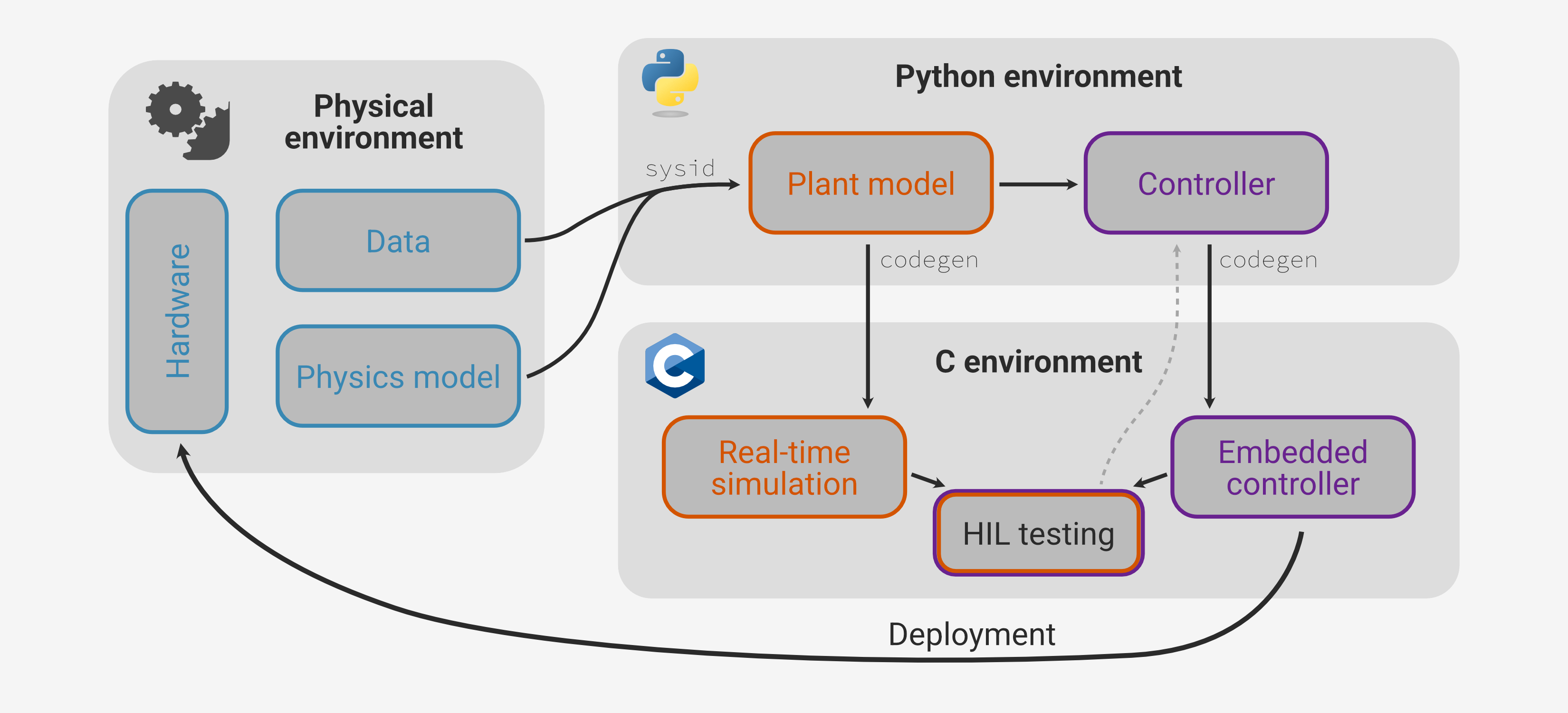
So far we’ve covered:
Specification of the physical system (Part 1)
Characterization of the system (Part 2)
Controller design and simulation (Part 3)
HIL testing validation (Part 4)
All that’s left is to run the controller on the actual hardware!
This final entry in the series will be much lighter than the previous parts, because we’ve already done the hard work. By including the HIL testing stage and being careful to construct a plant model that precisely matches the I/O of the physical system, all we need to do is swap the leads from the HIL board to the motor control circuit and re-run the test sequence.
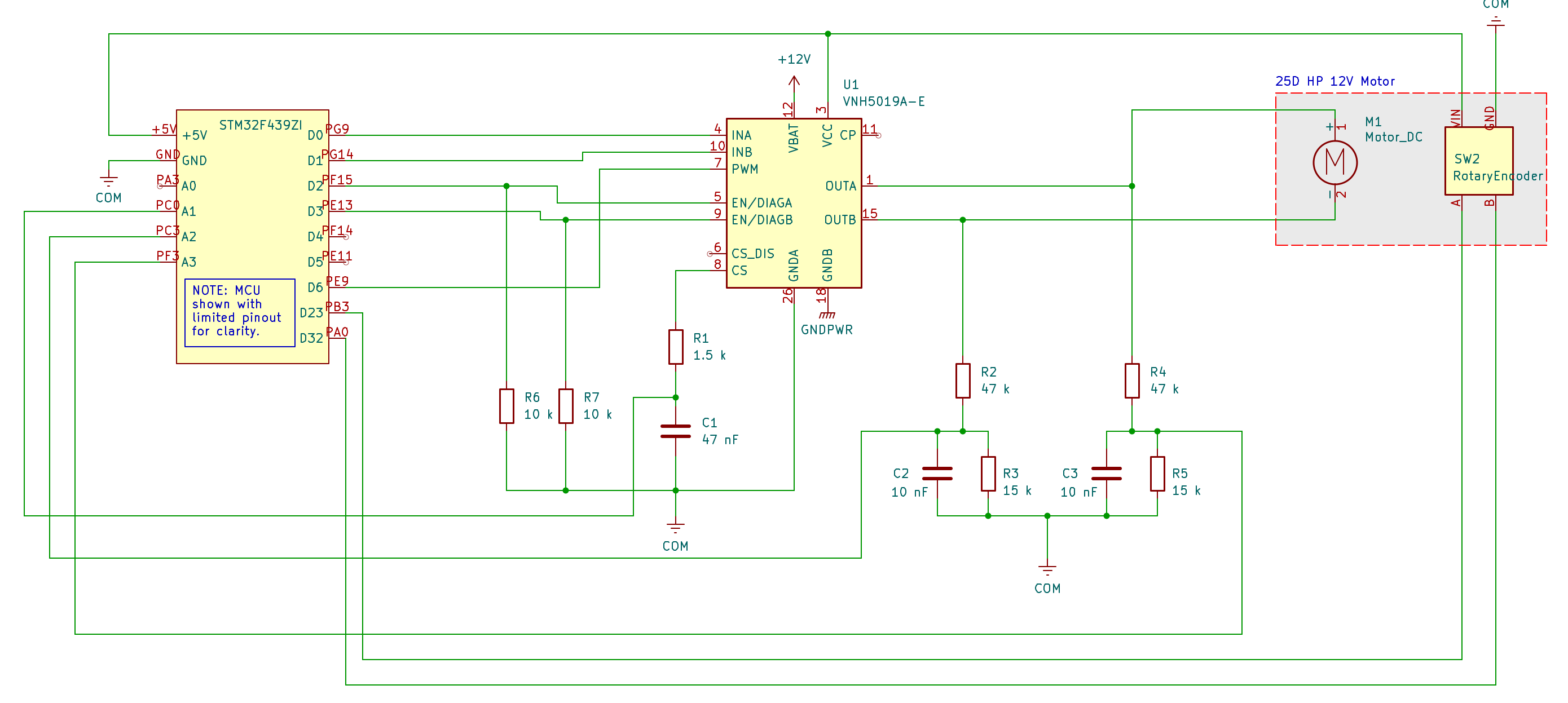
The circuit is the same as the one we used for the step response in Part 2:
Analyzing the experimental results¶
We can also re-use the serial communication script to collect the test data:
python serial_receive.py --save deployed_data.csv
How does the real thing compare to simulation and HIL test?
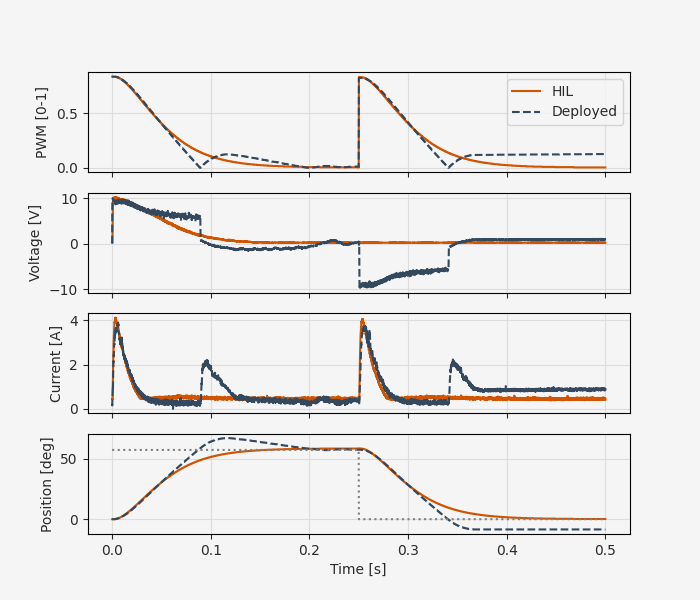
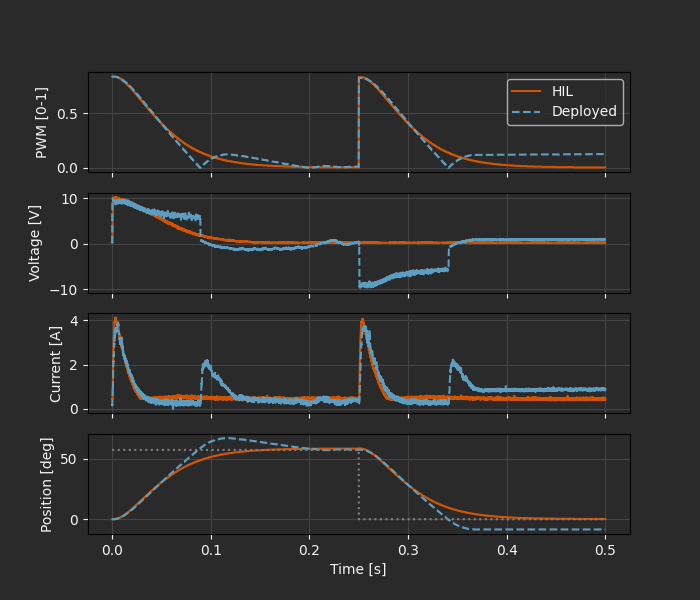
The correspondence here is not quite as good as it was between HIL and simulation. To some extent, this is to be expected - after all, we’re now running with the real physics. On the other hand, our calibrated model matched the step response data quite well, and we’re still mostly avoiding regimes where unmodeled effects like static friction and backlash would play a major role. So it’s worth taking a moment to inspect these results and see if we can identify the source of the divergence.
The simplest relationship in this data is between PWM duty cycle and voltage. The idealized relationship is a linear model
where \(V_0\) is the supply voltage. We were able to roughly confirm this with the ramp test in Part 2.
In reality though, the supplied voltage to the motor stays persistently above the predicted value from 60-80 ms, even as the PWM duty cycle drops below the simulation trace as the feedback controller tries to decrease the input voltage. Then there is a sharp drop in voltage as the control signal crosses zero and the polarity flips, leading to a spike in current and an overshoot of the target position.
This causal analysis immediately lets us zero in on the main source of the discrepancy! Some part of the power system (most likely the cheap 12V “wall wart” supply) has its own internal dynamics, causing \(V(t)\) to lag behind \(u(t)\). Most of the other deviations follow directly from this behavior.
The other discrepancy we might notice is a persistent position error towards the end of the test sequence. Again, we can quickly zero in on the problem. The persistent small error leads the PI controller to output a 10-15% duty cycle and corresponding current (slowly increasing due to integral action), but the position does not appear to respond. However, referring back to the “non-ideal effects” explored at the end of Part 2, we can guess that this is solidly in the static friction regime, where additional torque will have no effect on position until the “breakaway torque” threshold.
The observation that the power supply has unmodeled internal dynamics and that static friction causes problems for accurate position tracking with a pure PI controller are enough to send us on another iteration of the design loop. We might proceed by:
Designing characterization tests that will highlight the unmodeled (like a chirp response)
Adding non-ideal effects like Coulomb friction and power supply dynamics to the physics model
Calibrating parameters of the non-ideal model using the new test data
Revising the control architecture to consider static friction and power supply effects
Re-doing the HIL and deployment tests with the revised model and controller
All of this development can proceed with the same workflow we’ve already followed; we just go back to the top and add another level of fidelity. The advantage of this kind of structured development workflow is not that you don’t need to iterate, it’s that the iteration can happen at a faster pace because of the direct path from your Python code to hardware deployment.
Lessons learned¶
We’ve already seen two examples of how this approach to control systems development can pay dividends in troublshooting and rapid iteration. First, at the end of Part 4 we gave a brief anecdote about a misadventure in premature optimization of the control algorithm (the IMC-tuned cascaded controller). This controller looked good on paper, but fell apart as soon as it was put into HIL testing, giving us quick and easy feedback that it was not going to work in practice.
Then, by comparing the HIL results with the actual motor performance, we were able to quickly zero in on two problem areas for the physics model and controller, without needing to do any hardware troubleshooting. One key is the incremental nature of the development; since each stage from simulation to HIL testing to deployment is limited in scope, the number of possibilities for bugs and other problems is reduced. The process is also accelerated by having a single “source of truth” in the Python code. We can do parameter estimation, controller design, HIL testing, and hardware deployment using the same models and control algorithm.
Where to go from here¶
This series builds on various Archimedes concepts, including:
If you aren’t familiar with any of these, this is a great time to dig deeper and see how these combine to enable this end-to-end development workflow.
But the obvious next step is to go build something! How would you map your next project onto this workflow? What would you keep, add, or customize to make it fit your needs and preferences? While the path to hardware in Archimedes is still in the early stages of development, it is central to the Archimedes project. If you’re using Archimedes for hardware development and have questions, comments, or requests, please don’t hesitate to reach out!